
Can foundation models only be large?
Or can they be composable instead?

Foundation model?
The name“foundation model” intuitively suggests a support layer for building other applications or models. However, foundation models appear to be instead ever growing entities, insatiable devourers of data and resources (including our attention since a new best model is announced a few times a year), aspiring to become general encyclopedic model or event omniscient models. How did we get there, and this is the only way to think about foundation models?
The definition, or rather the definitions, for foundation models can be argued to be counter intuitive: https://en.wikipedia.org/wiki/Foundation_model. There is relatively little there that considers the models as an initial building layer. They are instead defined by:
The breadth of data they are trained on.
The size of the model: 1B parameters at minimum for some definitions. This leads foundation models to be called LxMs. For example, Large Language Models (LLMs), Large Reasoning Models (LRMs), Large Vision Models (LVMs).
Their applicability in a wide range of contexts, tasks, or operations.
While the model's fitness as a building block can be inferred from its wide applicability in point 3, this "foundation" aspect is not a formal part of its definition. The focus on size is a misinterpretation of the 'foundation' concept. Great pyramids are large, but do not have the ideal shape of foundations. I argue that a model's true value as a foundation lies not in its size, but in its reusability and adaptability as a component.
Encyclopedic inventory of patterns
In order to be applicable to a wide range of context, foundation models share in common that they build internal representation of patterns in the data, either completely unsupervised (e.g., LLMs trying to reconstruct masked portions of text in training data1) or as part of supervised efforts (e.g., LVMs using annotated images for training). The potential of foundation models for being useful to several applications comes from the volume of interleaved patterns they capture, but the task of composing usages of the models is left to downstream users.
In other words, foundation models are primarily defined as captures of the training data into encyclopedic inventories of association patterns. It is therefore natural to have them defined through, first, the breadth of the training data used followed by the the complexity of the model in order to extract and retain many patterns in the data as possible. However, this reliance on mere observations from data that is otherwise always connected to a broader context leads to trying to build ever broadening general encyclopedic or omniscient models in order to capture the most patterns.
An illustration of that is that the volume of training data has increased rapidly, along with the complexity of the models (architecture and number of parameters), as this led to rapidly increasing performance for LxMs. The breadth of data the model are trained on has now expanded to the point where we are approaching the time when the volume of text used for LLM training will correspond to the volume of public text available to mankind2, and astoundingly large images collections available through ubiquitous camera and image sharing platforms have been used for LVMs.
The race for benchmark performance has further led to expanding training data through the addition of data type to the training of a model. The new frontier is seemingly Large Multimodal Models. When pushing this approach to its conclusion there are no foundation models anymore, only The Grand Model That Knows It All Because It Saw It All. The foundation models converge toward a total model. Independently of whether that race for comprehensiveness through training data expansion succeeds, it can only be considered by a limited number of entities; this is a race bankrolled beyond the means of most companies.
Escaping the attraction of size inflation
Still, building foundation models should not be considered limited to tech titans, hopeful challengers with differentiating approaches to AI, or technical virtuosity (and commensurate funding to support it all). There is a significant need for models that are designed as robust, clearly shaped, well described, and easy-to-use building blocks. This means focusing on a well-defined scope and relevant training data, rather than striving for universality.
An example is a recent deep learning model for plant identification3. While not universal, as the model would not be of any help for self-driving vehicles or augmented vision for laparoscopic surgery in most situations, the model can be useful across a range of tasks in agriculture, gardening, nature conservation: automation, assistance software, reporting. It is important to point out that while the model simply a classifier, the use of deep learning at its core makes it compatible with model derivation techniques common to foundation models (fine tuning, LoRA) described later in this post. This model achieves reported leading performances using 10 million parameters, that is orders of magnitude less than the minimum of 1 billion parameters mentioned in the Wikipedia page for foundation models. An even more recent opinion article in Nature discusses foundation models for molecular cell biology4. scGPT, a single cell foundation model cited in that article, had a reported 53 million parameters in late 2023, placing it well under the billion parameters threshold. For comparison, chatGPT 3.5 released in 2022 had well over 1B parameter it is smallest variant and 175B parameters in its largest.
Being a foundation model might not require it to be a behemoth. Much smaller specialized models could be useful across a relative wide range of applications and use cases. How well they scope a problem space, or often a knowledge or data space, they cover, and additional characteristics to further facilitate their use and integration, can be argued to be a defining characteristic that makes them foundation models.
Usage as a foundation
We have seen that the aspects of the models about scope and interfaces that facilitate its use or integration across use-cases, could be argued to make the model a foundation more than the sheer size of the model, a consequence of the breadth of the training data.
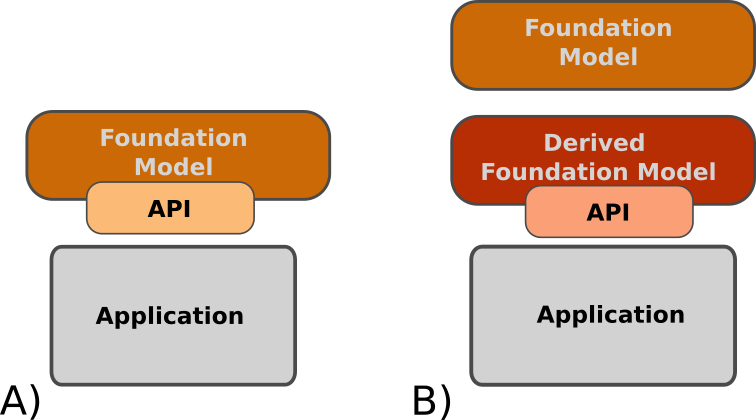
Application Programming Interfaces (APIs) are traditionally how to think about interfaces to software components are thought of. This can also be the case for foundation models, but there is an added possible layer upstream of the API: the customization of the model. We group ways to use foundation models into these two high-level categories:
API calls
Derived model (from a foundation models). Derivatives of foundation models will themselves be more directly integrated in a software sense through a API. That API can match the original foundation model, or be specific to the derived model. The resulting derived model can also be a foundation.
Usage scenarios involving derived models can help achieve better performance (compute cost, “correctness”, fit to the problem) that is hard or impossible to achieve through only API calls on the original foundation model, as well as be harder to replicate by competitors, There is no free lunch though. This comes at the cost of requiring the expertise to create that derived model, as well as maintain it in a scenario where the original foundation model will evolve.
Prompting [API call]
Prompting is essentially formulating what is needed using language, providing context that narrows down how to interpret the question and what is the type of output expected. Over time large language models have refined prompting (e.g., system prompt vs user prompt) and further added the notion of conversations as contextual units. Going over this in more details is beyond the scope of this post.
This is the most direct and easiest use of a foundation model. In the span of less than a year, prompt engineering went from job of the future in early 20235, technology oracles able to better speak to foundation models with natural language interfaces, to a more mundane general recommendation to formulate questions well6 and occasional “cooking recipes” for types of questions. In addition to this, several LxM foundation models are available as services (Software as a Service, SaaS, with subscriptions or cost per volume), or in self-managed form.
Prompting in its broadest sense is primarily for foundation models taking natural language as at least of the inputs. It can be useful to think about the more general notion of interrogating a model, but when natural language is not involved the flexibility for what can be asked to the model is much reduced. For example, we presented earlier the notion of smaller non-language models as foundation models (for example the plant identifier). The model tries to identify a plant in responses to pictures of different parts of the plant and this is pretty much it. If in-context learning is thought of as a type of prompting, there are relatively straightforward non-language examples.
In-context Learning [API call]
In context learning can be thought of as a type of prompt where examples of what is expected are provided instead of textual directions. Because of this, it is as easy to use as prompting, although what it requested is subject to more “interpretation” by the model. The example below uses Gemini 2.5 Flash to demonstrate how in-context learning can work, and the ability of the model to infer latent information thanks to the broad data it was trained on. Here our three short lists of products imply that they are for fruits, vegetables, and nuts without telling it directly.
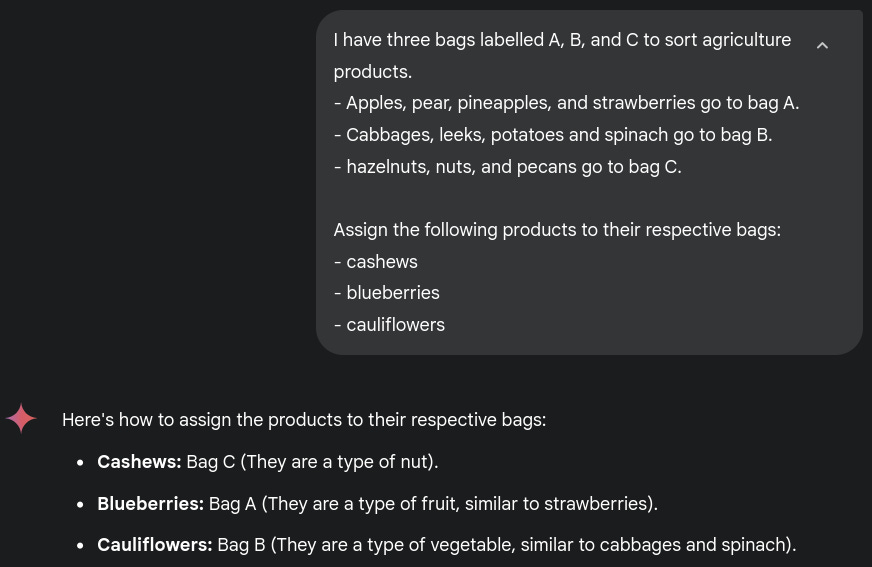
LLMs originated the notion of foundation models, and as a consequence concepts pertaining to text and language still dominate the discourse. In-context learning does not have be natural language, and non-language example can be though of. For example, a large visual model could be feed examples of image transformations as (original, result) pairs before an image to be transformed.
Fine tuning [Derived model]
Fine tuning is a substantial step up in cost & difficulty to use a foundation model. It is taking the AI model and running it through specialized data, which can be proprietary data, to “tune” it for those and often for a specific task. When considering state-of-the-art models have billions to trillions of parameters, which can make it a significant effort requiring two expensive resources: highly-skilled professionals and specialized hardware (Graphical Processing Units - GPUs), although this can be mitigated through parts of the model pinned down while only specific part are allowed to be modified through fine tuning.
Fine tuning techniques and pitfalls are out of scope for this post, but one is particularly important to keep in mind when considering the foundation aspect of the model. Fine tuning can result in a model “forgetting” what it was trained on. Checking whether the case, or preventing it from happening, can increase the cost and complexity of the training effort. Here again, how to achieve this is well beyond the scope of this post, but in many cases the derived models cannot aim at being complete augmentation of the original foundation model but only narrow or specialized versions of it.
Another noteworthy point is that the cost and size issues tend to disappear when not considering a gigantic foundation model. The ability to fine tune offered by artificial neural network can make many models “foundation models” when the criteria is potential for reuse across different contexts, tasks or operations independently of the model size.
Distillation [Derived model]
The promise of LxMs is that they contain multitudes, but this is at the cost of be large therefore relatively expensive or complex to use or self-manage. For a given context, task, or operation a smaller sub-model can often be “extracted”, which is a process called model distillation. It can be thought of as a form of fine tuning that focuses on performance (size of the model, amount of compute required for inference) for a subset of the contexts, tasks, or applications the foundation model can be used for.
Like with fine tuning this is a substantial step up in complexity and cost to build compare to using using a foundation model off-the-shelf with prompts. The operating cost savings (cost of compute, ability to deploy on more modest hardware) can be substantial though. Distillation is implicitly a form of specialization, and it inherits a lot of the technical complexity required to achieve fine tuning in addition to its own. Distillation is largely only relevant for large foundation models.
Low Rank Adaptation (LoRA) [Derived model]
Low Rank Adaptation is conceptually a form of fine tuning. In a nutshell, it is akin to inserting lightweight extensions between existing elements of a model, and, and train that new model while only allowing the added parameters in these extension to be modified by the process. Advantage of LoRA over fine tuning is lower number of parameters allowed to vary and lower volume of training data, making the training cheaper, and the property that these lightweight insertions can be swapped to switch between different specializations of a foundation model.
Model composition [Derived model]
Finally, more complex extensions can be bolted to foundation models, or foundation models be connected with one another, with the intent of augmenting what the foundation model can do alone. For example, this can be starting point to build multimodal models. A simple demonstration of this is LLaVA5, a vision-language model that essentially stitches together an LLM and a visual encoder with a simple additional layer trained to project the ouput of the image encoder into the same word embedding space as text is for the LLM.
All approaches to derived models we enumerated before can be considered in combination, and this is could be how a lot of innovation and competitive specialized solutions are built without the need to have access to gargantuan resources.
From foundation models to component models
Foundation models are defined to be so in great part because of their size, a consequence of wanting to capture all patterns in broad datasets. Only a small number of entities can compete on creating them, and when following that all encompassing logic we converge toward one universal model.
However, the relevance and convenience of model as a building block for new contexts, tasks, or operations could be the most desirable trait. This makes building specialized foundation models, either from scratch or as derivatives of larger foundation models, a more practical and efficient strategy than pursuing a single, universal model, which may not be the optimal solution for dedicated tasks until hypothetical superhuman AGI breakthroughs.
Furthermore, deep learning model architectures allow model derivation with techniques such as fine tuning, model distillation, or low rank adaptation. They create opportunities for fluid model re-use, and the thinking could shift from foundation models aspiring as universality to composable or component models.
This change in mindset would point toward AI development that is more accessible, modular, and tailored, moving away from a monolithic approach. In this sense it would mirror software development where modular architectures help meet the demands of modern system for adaptability, scalability, and maintainability.
Raschka, Sebastian. Build a Large Language Model (From Scratch). Simon and Schuster, 2024.
Villalobos, Pablo, et al. "Position: Will we run out of data? Limits of LLM scaling based on human-generated data." Forty-first International Conference on Machine Learning. 2024. https://openreview.net/forum?id=ViZcgDQjyG
Lapkovskis, A., Nefedova, N., & Beikmohammadi, A. (2024). Automatic Fused Multimodal Deep Learning for Plant Identification. ArXiv, abs/2406.01455.
Cui, H., Tejada-Lapuerta, A., Brbić, M. et al. Towards multimodal foundation models in molecular cell biology. Nature 640, 623–633 (2025). https://doi.org/10.1038/s41586-025-08710-y
Liu, Haotian; Li, Chunyuan; Wu, Qingyang; Lee, Yong Jae (2023-12-15). "Visual Instruction Tuning". Advances in Neural Information Processing Systems. 36: 34892–34916.